
テキストマイニングを一通りやってみた。
- まず、Twitterのデータを抽出する。各種ツールがあるようだが、JavaScriptベースのウェブアプリケーションを使った。スクリプトがネットに落ちているのでそれを改良する。Twitterの仕様上一度に取得できるデータは100件まで。時間を置いて取得しなおせばデータを蓄積することはできる。
- 次にttmというツールにデータを食わせる。Shift-JIsのタグ付きCSVという特殊な形になっている。TwitterのデータはUTF-8なので、整形とテキストエンコーディングの変更が必要。タグは何でもよいみたいだ。今回はMacで作業したが、Mac版では辞書の読み込みなどはしなくても良いみたいだ。ttmのダウンロードはこちら。
- ttmでデータを加工したら、今度はRにフィードする。なぜかcsvの2行目と2列目(ここには品詞)が入っているを削除する必要がある。
- Rで加工する。igraphというパッケージを使い、最後にtkplotでグラフデータを描画して終わり。
このようなグラフができる。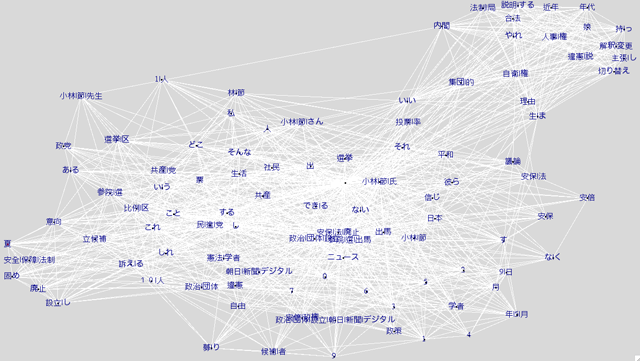
これは「小林節」で検索したもの。実際には630 x 254のマトリックスになった。これを全てプロットすると読めなくなくなる。まだニュースが出てすぐなので「ニュースをそのまま伝える」中立的な内容が多い。もちろん、肯定的なデータや否定的なデータが混じっている。いちおうPostScriptで保存できるのだが、日本語データが全て飛んでいた。
このレベルだと実際に文章を読んだ方が早い。100しかないのだから、肯定的な呟きと否定的な呟きを分類すればよいわけだ。
試しに「民主党」でも試してみたのだが、こちらは誹謗中傷ツイートが多い。なぜか同じような文面をコピペしたものばかりである。テキストマイニングなので、当然情報の信憑性までは審議できないのだ。噂によると工作員がいるということなのだが、普段Twitterをしていても全く目にしないものばかりだ。広がりという点でどうなのだろう、などと思う。